Arxiv 2023
SpeechAct: Towards Generating Whole-body Motion from Speech
Jinsong Zhang1#, Minjie Zhu1#, Yuxiang Zhang2, Yebin Liu2, Kun Li1*
1 Tianjin University 2 Tsinghua University
# Equal contribution * Corresponding author
[Code] [Arxiv]

Abstract
This paper addresses the problem of generating whole-body motion from speech. Despite great successes, prior methods still struggle to produce reasonable and diverse whole-body motions from speech. This is due to their reliance on suboptimal representations and a lack of strategies for generating diverse results. To address these challenges, we present a novel hybrid point representation to achieve accurate and continuous motion generation, e.g., avoiding foot skating, and this representation can be transformed into an easy-to-use representation, i.e., SMPL-X body mesh, for many applications. To generate whole-body motion from speech, for facial motion, closely tied to the audio signal, we introduce an encoder-decoder architecture to achieve deterministic outcomes. However, for the body and hands, which have weaker connections to the audio signal, we aim to generate diverse yet reasonable motions. To boost diversity in motion generation, we propose a contrastive motion learning method to encourage the model to produce more distinctive representations. Specifically, we design a robust VQ-VAE to learn a quantized motion codebook using our hybrid representation. Then, we regress the motion representation from the audio signal by a translation model employing our contrastive motion learning method. Experimental results validate the superior performance and the correctness of our model.
Method
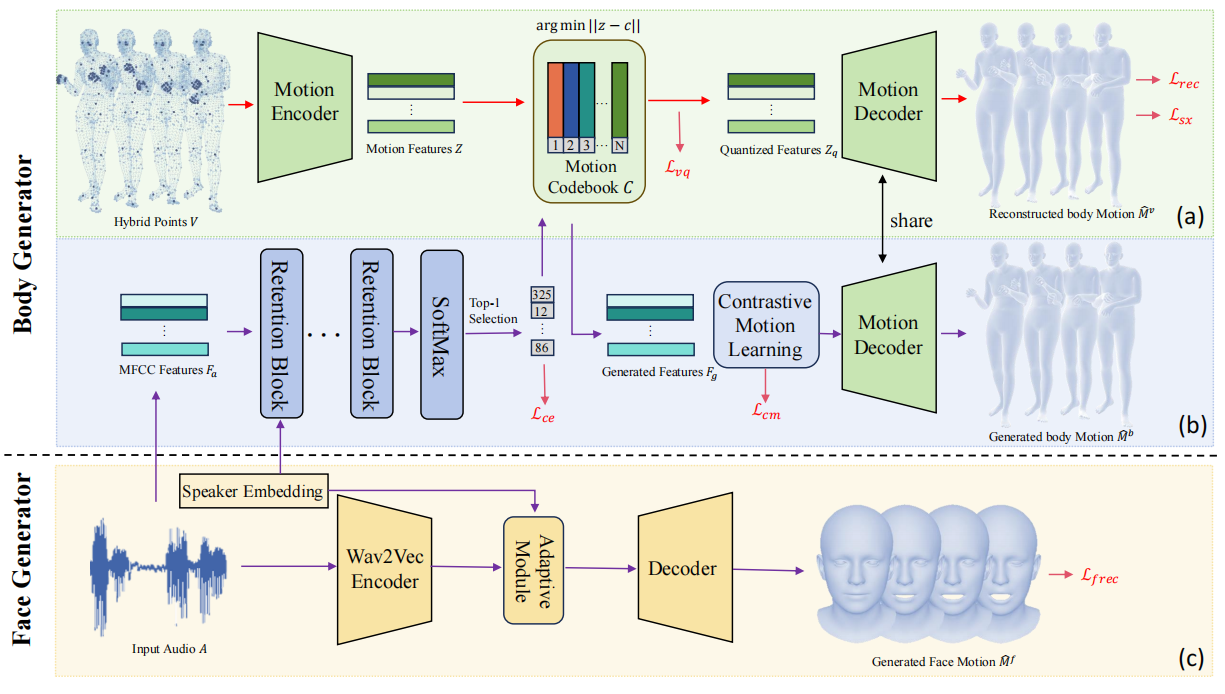
Fig 1. The overview of our framework.
Demo
Technical Paper

Citation
Jinsong Zhang, Minjie Zhu, Yuxiang Zhang, Yebin Liu, Kun Li. "SpeechAct: Towards Generating Whole-body Motion from Speech". arXiv preprint arXiv:2311.17425, 2023.
@article{zhang2023speech,
author = {Jinsong Zhang and Minjie Zhu and Yuxiang Zhang and Yebin Liu and Kun Li},
title = {SpeechAct: Towards Generating Whole-body Motion from Speech},
journal={arXiv preprint arXiv:2311.17425},
year={2023},
}